
- 이번 글에서는 머신러닝에 대한 기본적인 이해와 필수로 따라오는 탐색적 데이터 분석에 대해 학습하고자 한다.
0. 준비하기
- 이번 코드 실습 데이터는 kaggle의 bike sharing 데이터를 이용할 것이고, 미리 다운받은 경로에서 필요한 데이터를 판다스를 이용해 가져오도록 하자.
- 처음 코드는 구글 드라이브를 구글 colab 환경에 연결하기 위하여 필요한 코드를 입력한 것이다. 드라이브를 마운트하면 구글 드라이브 파일 및 디렉토리에 쉽게 액세스할 수 있다.

1. 데이터 확인
- 독립변수
- datetime : 1시간 간격 데이터 수집
- season : 봄/여/가/겨 1,2,3,4
- holiday : 0 공휴일 아님, 1 공휴일
- workingday : 0 평일이 아님, 1: 평일
- weather : 1 맑음 2 약간 흐림 3 약한 눈,비 4 폭우, 폭설(기상이 매우 안좋은) . . 등이 있고
- 종속 변수
- count(자전거 대여 수량)
2. 문제 정의
- 각 독립변수에 따른 자전거 대여 수량을 예측하고자 함.
3. 날짜 데이터 변환
- datetime 컬럼의 값들을 좀 더 세분화하여, 새로운 컬럼으로 날짜 관련 컬럼을 생성해줄 필요성이 있음.
- 흔히 사용하는 방법으로 " pd.to_datetime(DF['datetime']) " 코드를 이용하여 데이터 타입을 datetime으로 바꾼 뒤에
---> 아래와 같이 메서드를 이용하는 방법이 있고,

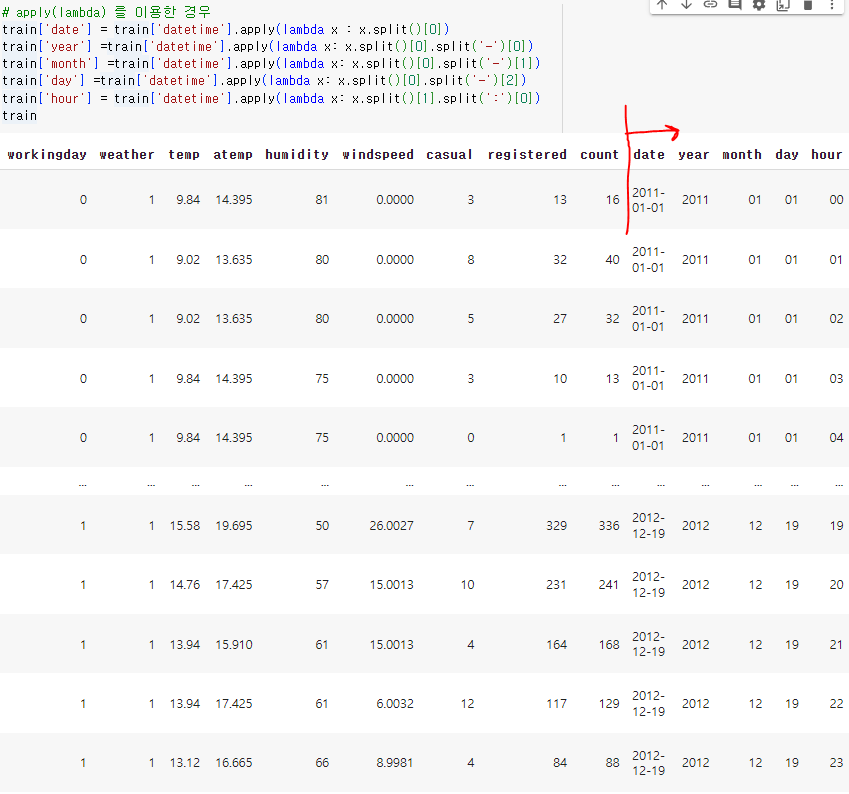
- 이번 글에서는 apply(lambda) 를 이용한 경우를 배워보겠다. 다음과 같이 코드를 이용하면, 데이터 프레임에 다음과 같이 날짜 관련 컬럼들이 각각 추가된다.

- .split() 메서드는 공백을 기준으로 데이터를 분리하는 것이고, 첫번째 값은 2011-01-01인 날짜 두번째 값은 시간인 00:00:00 이 되는 것이다.
- 그 첫번째값을 '-'을 기준으로 연/월/일을 나누는 코드이고, 두번째 값은 ' : '을 기준으로 시 를 추출했다(분 초는 어차피 다 0인 자료).
- 다음으로 날짜에 포함되는 요일 컬럼도 생성해보자. 이번에는 datetime 모듈에서 제공하는 메서드들을 사용하는 순서로 소개하겠다.
1) 문자열을 날짜와 시간 객체로 변환해주는 .strptime(string parse time의 약자) 메서드로 문자열을 날짜와 시간 객체로 변환
2) weekday() 메서드로 요일 고유 값을 정수로 반환
3) day_name[] 에 반환된 값을 넣어 요일명으로 반환해주는 방법이다.

- 이것을 다시 apply lambda 버전으로 코딩해보면 다음과 같이 weekday 컬럼과 데이터들을 추가할 수 있다.

4. 시각화를 통한 탐색적 데이터 분석
4-1 데이터 매핑하기
- 필수적인 과정은 아니지만, 시각화의 목적인 "보기좋게"를 위하여 필자는 다음과 같이 정수형 데이터들을 매핑하였다.

4-2 한글 폰트 적용
- 먼저 다음 코드들을 실행해준 뒤, 완료가 되면 런타임 연결해제 후 코드들을 재실행해주면 되겠다.

4-3 시각화 그래프 예시(계절별 대여수)


4-4 시각화의 목적
- 원론적인 이야기를 잠시 해보자면, 머신러닝에 필수적으로 따라오는 것은 Feature Engineering이다. Feature Engineering이란 쉽게 말해 머신러닝 알고리즘에 적용할 독립변수를 찾아서 넣어주는 과정이라고 생각하면 된다.
- 미래 예측 모델을 만들 때, 우리가 사용하려는 독립변수 X가 종속변수 Y라는 결과에 정말로 중요한 영향을 끼치는 변수일까? 라는 물음을 던지는 것이 중요한 포인트이다. 다른 독립변수 같아 보이지만 사실상 중복되는 변수일 수도 있고, 종속변수를 예측하는 데에는 중요하지 않은 변수일 수도 있고 그러한 모든 변수들을 분류하고 적절하게 전처리하는 과정을 "탐색적 데이터 분석(EDA)" 라고 설명할 수 있겠다.
* 한편 머신러닝 매우 쉽게 이해하기.
기울기 a X 독립변수 1 + 기울기 b X 독립변수 2 + ... 기울기 k X 독립변수 n = 종속변수 Y인 모델에서 독립변수들의 기울기를 찾는 과정이라고 생각하면 된다.
정형데이터 컬럼(지금 처럼)이 존재하고 그걸 추리는 건 => 분석가의 도메인 지식 = 머신러닝!
비정형데이터(이미지, 영상, 음성) 그걸 추리는 건 => 알고리즘 = 딥러닝!
다시 돌아와서 시각화도 탐색적 데이터의 분석에서 아주 중요한 도구로서 작용한다. 다음의 과정이 이를 설명할 것이다.
5. 종속변수 로그변환
- 일부 통계 분석 및 모델링 기법은 종속 변수가 정규분포를 따를 때 더 잘 동작한다. 로그 변환은 종속 변수를 더 정규분포에 가깝게 만들어 이러한 가정을 만족시키기 위함이다.
- 이번 분석에서도 종속변수 count가 윗부분 그래프 처럼 정규하지 않으므로, " sns.histplot(np.log(train['count'])) "코드로 종속변수를 보다 정규하도록 로그변환해주자.
- 물론 이후에 최종예측할 때에는 다시 지수변환으로 변경해서 예측해주어야한다.

6. 독립변수 추리기
- 다음은 각 독립변수들과 종속변수들의 관계를 한 눈에 볼 수 있도록 막대그래프를 통해 시각화한 결과이다.
fig, ax = plt.subplots(nrows =3, ncols = 3, figsize=(17,12))
sns.barplot(x = 'year', y = 'count', data = train, ax = ax[0,0])
sns.barplot(x = 'month', y = 'count', data = train, ax = ax[0,1])
sns.barplot(x = 'holiday', y = 'count', data = train, ax = ax[0,2])
sns.barplot(x = 'workingday', y = 'count', data = train, ax = ax[1,0])
sns.barplot(x = 'weather', y = 'count', data = train, ax = ax[1,1])
sns.barplot(x = 'month', y = 'count', data = train, ax = ax[1,2])
sns.barplot(x = 'season', y = 'count', data = train, ax = ax[2,0])
sns.barplot(x = 'day', y = 'count', data = train, ax = ax[2,1])
sns.barplot(x = 'weekday', y = 'count', data = train, ax = ax[2,2])
plt.tight_layout()
plt.show()
- 먼저 day는 train.csv 에 1~19 , test.csv에 20-31의 자료가 있으므로 제외한다.
- 그리고 유의미한 영향을 끼칠 것 같은 몇 변수들(season, weather, weekday, holiday)을 대상으로는 boxplot으로 다시 한 번 시각화를 진행해보자.
fig, ax = plt.subplots(nrows =2, ncols = 2, figsize=(17,12))
sns.boxplot(x = 'season', y = 'count', data = train, ax = ax[0,0])
sns.boxplot(x = 'weather', y = 'count', data = train, ax = ax[0,1])
sns.boxplot(x = 'weekday', y = 'count', data = train, ax = ax[1,0])
sns.boxplot(x = 'holiday', y = 'count', data = train, ax = ax[1,1])
plt.tight_layout()
plt.show()
- 여기서는 두 가지 견해를 낼 수 있을 것이다. holiday 변수는 weekday가 포괄할 수 있는 값이니 큰 차이가 없다면 귀속하도록 하자.
- weather에 보면 강한 눈비가 다른 값들과 달리 조금 이상한 것을 발견할 수 있다.
※ 이상치 확인하기
- pointplot 그래프를 이용해서 더 확실하게 확인해보면, 아래 부분 그래프인데 점이 한개만 찍혀있고 다른 값들과는 조금 다른 양상을 띄는 것을 확실하게 구분해볼 수 있다.
fig, ax = plt.subplots(nrows = 2, figsize=(15,10))
sns.pointplot(x = 'hour', y = 'count', hue = 'season', data = train, ax = ax[0])
sns.pointplot(x = 'hour', y = 'count', hue = 'weather', data = train, ax = ax[1])
plt.tight_layout()
plt.show()
- 아니나 다를까 value_counts()를 통해 확인해보았을 때, 이는 시스템 이상이 있었거나 데이터를 받아오면서 문제가 생긴것은 분명해보인다. 실무에서는 PM님께 보고를 하여 데이터 베이스 관리 담당 개발자에게 확인을 요청하거나 하면 되겠다.

- 이전에 말했던 시각화의 목적이 바로 여기에서 설명되는 것이다. 시각화를 통해 단순히 파악하기는 어려운 이상치들을 파악할 수 있는 것이다. 일단 여기서는 강한눈비로 표기된 행 하나를 제거하는 것으로 결정하겠다.
※ 다시 독립변수 추리기로 돌아와서
이전에 추리지 않았던 변수들에 대한 회귀선과 산점도를 그려보자.
fig, ax = plt.subplots(nrows =2, ncols = 2, figsize=(15,10))
sns.regplot(x='temp', y='count', data=train, line_kws={'color': 'red'}, ax=ax[0, 0])
sns.regplot(x='atemp', y='count', data=train, line_kws={'color': 'red'}, ax=ax[0, 1])
sns.regplot(x='windspeed', y='count', data=train, line_kws={'color': 'red'}, ax=ax[1, 0])
sns.regplot(x='humidity', y='count', data=train, line_kws={'color': 'red'}, ax=ax[1, 1])
plt.tight_layout()
plt.show()
- 먼저 우하향하며 기울기가 비교적 유의미한 영향을 끼칠 것으로 판단되는 "humidity" 습도 데이터를 독립변수로 결정해보겠다.
- 다음으로 우상향 그래프 중에서는 조금더 기울기가 가파른 temp와 atemp 를 주목해볼 수 있겠다. temp는 관측온도, atemp는 체감온도이다. 여기서는 이제 도메인 지식 등 기타 다른 내용들을 바탕으로 판단해볼 수 있겠지만, 필자는 습도나 다른 요인들을 종합적으로 판단하여 얻어지는 체감온도인 atemp를 제외하고 temp를 독립변수로서 채택하는 것으로 결정하겠다.
7. 최종 INPUT 변수 설정

- 이 코드들은 예시로서 보는 것에 중점을 두길 바란다. 대표적으로 다중공손성 등 파악하지 못한 통계 이론이 많고, 도메인 지식 등을 개인의 직관(실무에서는 끊임없이 소통해야함)에 의해서만 결정했기 때문이다. 또한, 문자열로 매핑된 데이터들은 수치 데이터로 다시 변환을 해주어야한다.
- EDA를 거친 뒤 final_df를 새로 생성하고, 그 과정에서 이상치를 제거(train.loc ... != ...)하는 일련의 과정을 이해하고 구경하는 정도로서 이 게시글을 읽기를 바란다.
'IT & 개발공부 > 파이썬(Python)' 카테고리의 다른 글
| 머신러닝에서의 데이터 전처리 (0) | 2023.08.18 |
|---|---|
| 머신러닝과 교차검증(+ 하이퍼 파라미터 튜닝) (0) | 2023.08.17 |
| API 인증키를 활용한 웹 크롤링 실습 -3 (서울 열린데이터 광장) (0) | 2023.08.12 |
| API 인증키를 활용한 웹 크롤링 실습 -2 (공공데이터 포털 feat.xmltodict) (0) | 2023.08.12 |
| API 인증키를 활용한 웹 크롤링 실습 -1 (한국도로공사 데이터) (0) | 2023.08.11 |



