
0. 데이터 분석 및 이해
- 이번 프로젝트에서 전처리를 담당한 데이터는 버스 정류장 승하차 인원 데이터였다. 내가 담당하게 된 데이터는 사실 처음부터 팀원들의 우려가 많았다. 일단 해당 데이터는 서울시 전체의 버스정류장을 대상으로 하고 있는데, 전처리 조건은 강남구에 속한 데이터만 추출하는 것이었고 분류는... 되어있지 않았기 때문이다. 최악의 상황에는 몇 백개가 될지도 모르는 정류장을 하나 하나 찾아가며 매칭해야될 수도 있는 작업이었다.
- 일단 1개의 연도 데이터에 약 47만개 정도의 행이 존재했다. 서울시 정류장별 각 노선의 월별 승하차 데이터였기 때문이다. 정말 막막했는데 데이터를 잘 보니 버스 정류장별 ARS 번호라는 컬럼이 있었다. 각 정류장별 고유번호값이 지정이 되어있었는데, 생각해보니 분명 이 데이터를 수집하고 정리한 사람이 아무 이유도 없이 고유번호를 정했을까? 주민번호도 각 숫자 위치별로 의미가 있는데 공공데이터로서 수집하고 처리한 데이터이기 때문에 분명 번호에 의미가 있을 것이라는 생각이 들었다.
- 그런 생각이 든 이후로 엑셀로 CSV파일을 불러와 전체데이터를 살펴봤고, ARS 번호를 오름차순으로 정리하니 규칙성이 보이게 되었다. 특정 지역구가 모여있는 듯한 느낌을 받았기 때문이다. 또한 ARS 번호가 네이버 지도에도 같은 번호를 사용하고 있어서 파악이 용이했던 점도 다행이었다.
- 또한, 다행이었던 것은 서울 열린데이터 광장 해당 데이터 질문-답변에는 지역구별로 데이터를 구별할 방법이나 제공받을 수는 없다고 하였는데 개별적으로 문의한 결과 번호 추측한대로 앞 두자리를 보면 지역구마다 고유 코드가 있다는 것을 재차 확인할 수 있었다.
- 이후로는 팀에서 논의한대로 연도/분기/정류장코드/정류장이름/시간 구간별 승하차인원/X좌표/Y좌표를 컬럼으로 가진 데이터프레임으로 만들었다. 이어질 내용은 Jupyter lab으로 제작한 과정을 쓰도록 하겠다.
※ 본격 코드 작업
1. 엑셀 파일 사용을 위한 설치
- 버스 정류장 좌표 파일 하나가 excel 파일이라서 excel을 불러오기 위해 해당 라이브러리를 설치해주었다.

2. 데이터 불러오기
- 다음 코드를 이용하여 필요한 데이터들을 전부 불러와주었다.2020~2022 승하차 데이터와 그에 매칭시켜줄 정류장 X,Y좌표 파일
import pandas as pd
# 승하차 데이터 불러오기
df20 = pd.read_csv('data/bus_data/bus_2020.csv', encoding='cp949') # 서울시 버스노선별 정류장별 시간대별 승하차 인원 정보 2020년
df21 = pd.read_csv('data/bus_data/bus_2021.csv', encoding='cp949') # 서울시 버스노선별 정류장별 시간대별 승하차 인원 정보 2021년
df22 = pd.read_csv('data/bus_data/bus_2022.csv') # 서울시 버스노선별 정류장별 시간대별 승하차 인원 정보 2022년
# 좌표 데이터 불러오기
df_wgs1 = pd.read_csv('data/bus_data/seoul_bus_wgs84(2021.01.14).csv', encoding='cp949') # 서울시 버스정류소 위치정보(2021.01.14) 2020년용
df_wgs2 = pd.read_csv('data/bus_data/seoul_bus_wgs84(2022.03.29).csv', encoding='cp949') # 서울시 버스정류소 위치정보(2022.03.29) 2021년용
df_wgs3 = pd.read_excel('data/bus_data/seoul_bus_wgs84(2022.11.30).xlsx') # 서울시 버스정류소 위치정보(2022.11.30) 2022년용
3. 데이터 확인하기
- 다음과 같이 불러온 데이터들이 잘 불러와졌는지 확인해주었다. 나머지는 동일하므로 생략

4. 컬럼 제거하기
- 먼저 사용하지 않을 컬럼을 제거해주자
- 제거 목록
- 노선 번호, 노선명, 표준버스정류장 ID, 등록일자(2022년 자료의 MNTN_TYP_CD, MNTN_TYP_NM : 버스 종류 = 광역버스인지 마을버스인지 등)
- 좌표 데이터에서는 표준 ID(=정류소 ID, NODE_ID 각 자료별 이름이 다름)를 제거해주면 되겠다.

- 나머지 코드는 같은 이론이므로 생략하였다.
5. 필요한 행만 추출하기
- 이제 강남구 지역의 버스 정류장 데이터들만 가져온 뒤, 오름차순으로 정렬해보겠다.

5-1 데이터 파악
- 정류장명을 살펴보니 퇴계원 5리라는 값이 나오게 된다. 강남구만이 잘 추출된 것인지 알아보니 퇴계원 5리는 경기도 남양주시에 위치한 것으로 좌표 데이터를 봤을 때, 정확하게는 23100부터 강남구였음을 알 수 있다.

5-2 데이터 삭제
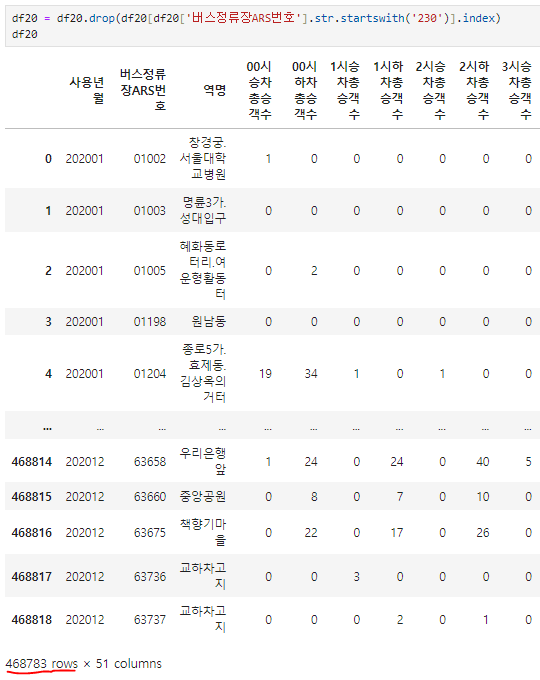
- 데이터를 재추출하기 위해 230으로 시작하는 데이터 행들을 다음과 같이 지워주도록 하자(2021,2022년 데이터도 동일)
- 468819 행에서 468783 행으로 줄어든 것을 확인할 수 있다.
5-3 데이터 재추출
- 이제 확실하게 강남구 데이터만을 추출하는 것이 가능하다.(2020년, 2022년)

* 특이사항으로 2021년 데이터는 조금 이상한 점이 있었다.
- 아래 오류는 해당 컬럼 등에 null 값이 있기 때문에 추출하는 것에 오류가 뜨는 상황인데,
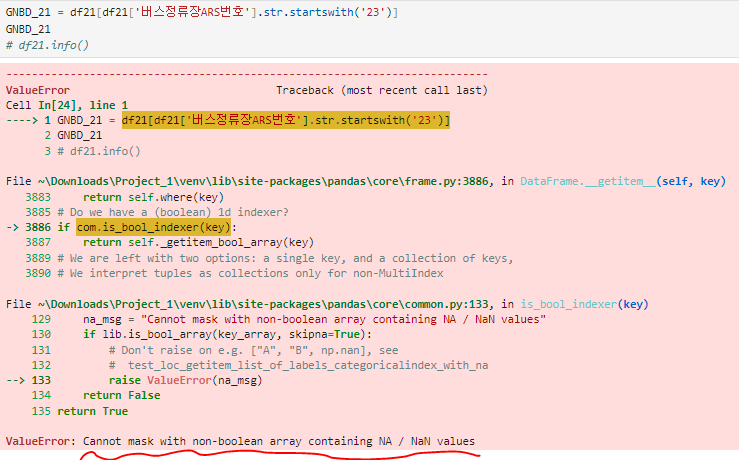
- 옵션을 통해 수정해봐도 해결이 안되고(실제 2021년 강남구 데이터는 25054개이다),

- 그렇지만... 실제로 null 값은 어디에도 없었다.
아래는 df21.info()의 결과이다.
<class 'pandas.core.frame.DataFrame'>
Index: 469313 entries, 0 to 469360
Data columns (total 51 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 사용년월 469313 non-null int64
1 버스정류장ARS번호 469313 non-null object
2 역명 469313 non-null object
3 00시승차총승객수 469313 non-null int64
4 00시하차총승객수 469313 non-null int64
5 1시승차총승객수 469313 non-null int64
6 1시하차총승객수 469313 non-null int64
7 2시승차총승객수 469313 non-null int64
8 2시하차총승객수 469313 non-null int64
9 3시승차총승객수 469313 non-null int64
10 3시하차총승객수 469313 non-null int64
11 4시승차총승객수 469313 non-null int64
12 4시하차총승객수 469313 non-null int64
13 5시승차총승객수 469313 non-null int64
14 5시하차총승객수 469313 non-null int64
15 6시승차총승객수 469313 non-null int64
16 6시하차총승객수 469313 non-null int64
17 7시승차총승객수 469313 non-null int64
18 7시하차총승객수 469313 non-null int64
19 8시승차총승객수 469313 non-null int64
20 8시하차총승객수 469313 non-null int64
21 9시승차총승객수 469313 non-null int64
22 9시하차총승객수 469313 non-null int64
23 10시승차총승객수 469313 non-null int64
24 10시하차총승객수 469313 non-null int64
25 11시승차총승객수 469313 non-null int64
26 11시하차총승객수 469313 non-null int64
27 12시승차총승객수 469313 non-null int64
28 12시하차총승객수 469313 non-null int64
29 13시승차총승객수 469313 non-null int64
30 13시하차총승객수 469313 non-null int64
31 14시승차총승객수 469313 non-null int64
32 14시하차총승객수 469313 non-null int64
33 15시승차총승객수 469313 non-null int64
34 15시하차총승객수 469313 non-null int64
35 16시승차총승객수 469313 non-null int64
36 16시하차총승객수 469313 non-null int64
37 17시승차총승객수 469313 non-null int64
38 17시하차총승객수 469313 non-null int64
39 18시승차총승객수 469313 non-null int64
40 18시하차총승객수 469313 non-null int64
41 19시승차총승객수 469313 non-null int64
42 19시하차총승객수 469313 non-null int64
43 20시승차총승객수 469313 non-null int64
44 20시하차총승객수 469313 non-null int64
45 21시승차총승객수 469313 non-null int64
46 21시하차총승객수 469313 non-null int64
47 22시승차총승객수 469313 non-null int64
48 22시하차총승객수 469313 non-null int64
49 23시승차총승객수 469313 non-null int64
50 23시하차총승객수 469313 non-null int64
dtypes: int64(49), object(2)
memory usage: 186.2+ MB
- 어차피 20년으로 하는 방법을 학습하였으니, 21년 데이터는 엑셀로 작업하여 불러왔다.
6. 좌표데이터와 버스데이터 merge
- 다음 코드를 이용하여 ARS-ID 를 기준으로 merge를 진행해준다. 다만 그 전에 GNBD_20의 ARS-ID를 int로 바꿔주도록 하자.

- left 조인으로 설정한 이유는 저기에 뜬 NaN이 바로 그 이유이다. 시내버스는 노선이 폐지되거나, 노선이 변경되는 등 시기에 따라 정확하게 정류장이 일치하지 않을 경우의 수도 존재하기 때문이다.
- 이러한 결측치들은 팀내부에서 논의한 결과 해당 시기에 해당 상권 매출에 영향을 끼쳤을 가능성이 있으므로 엑셀파일로 저장하여 직접 확인하고 결측치들을 채워주기로 결정하였다(조건이 다양하고,생략되어 표시되는 등 처리에 어려움이 있음).
- 한편, 가상 데이터들은 직접 거리를 재어 처리하거나 삭제해주도록 하자.
- 추가로 칼럼 정리 후 CSV 불러오기(컬럼 이름 통일)
7. 데이터 합치기
7-1. 시간 구간별 데이터 합치기
# 시간 구간별 데이터 합치기
temp3_mod['00~06_승하차_승객수'] = (
temp3_mod['00시승차총승객수'] + temp3_mod['00시하차총승객수'] +
temp3_mod['1시승차총승객수'] + temp3_mod['1시하차총승객수'] +
temp3_mod['2시승차총승객수'] + temp3_mod['2시하차총승객수'] +
temp3_mod['3시승차총승객수'] + temp3_mod['3시하차총승객수'] +
temp3_mod['4시승차총승객수'] + temp3_mod['4시하차총승객수'] +
temp3_mod['5시승차총승객수'] + temp3_mod['5시하차총승객수']
)
temp3_mod['06~11_승하차_승객수'] = (
temp3_mod['6시승차총승객수'] + temp3_mod['6시하차총승객수'] +
temp3_mod['7시승차총승객수'] + temp3_mod['7시하차총승객수'] +
temp3_mod['8시승차총승객수'] + temp3_mod['8시하차총승객수'] +
temp3_mod['9시승차총승객수'] + temp3_mod['9시하차총승객수'] +
temp3_mod['10시승차총승객수'] + temp3_mod['10시하차총승객수']
)
temp3_mod['11~14_승하차_승객수'] = (
temp3_mod['11시승차총승객수'] + temp3_mod['11시하차총승객수'] +
temp3_mod['12시승차총승객수'] + temp3_mod['12시하차총승객수'] +
temp3_mod['13시승차총승객수'] + temp3_mod['13시하차총승객수']
)
temp3_mod['14~17_승하차_승객수'] = (
temp3_mod['14시승차총승객수'] + temp3_mod['14시하차총승객수'] +
temp3_mod['15시승차총승객수'] + temp3_mod['15시하차총승객수'] +
temp3_mod['16시승차총승객수'] + temp3_mod['16시하차총승객수']
)
temp3_mod['17~21_승하차_승객수'] = (
temp3_mod['17시승차총승객수'] + temp3_mod['17시하차총승객수'] +
temp3_mod['18시승차총승객수'] + temp3_mod['18시하차총승객수'] +
temp3_mod['19시승차총승객수'] + temp3_mod['19시하차총승객수'] +
temp3_mod['20시승차총승객수'] + temp3_mod['20시하차총승객수']
)
temp3_mod['21~24_승하차_승객수'] = (
temp3_mod['21시승차총승객수'] + temp3_mod['21시하차총승객수'] +
temp3_mod['22시승차총승객수'] + temp3_mod['22시하차총승객수'] +
temp3_mod['23시승차총승객수'] + temp3_mod['23시하차총승객수']
)
temp3_mod
- 최초에는 가장 오른쪽 열에 컬럼이 추가됨.

- insert( ) 를 이용하여 컬럼 위치 이동시키기(pop으로 기존 컬럼은 제거)

*. insert ( ) 란?
- insert() 메서드는 판다스 데이터프레임에서 열(컬럼)을 특정 위치에 삽입할 때 사용하는 메서드입니다. 이 메서드를 사용하면 기존 열의 위치를 변경하거나 새로운 열을 삽입할 수 있습니다.
- insert() 메서드의 기본 구문은 다음과 같습니다
: DataFrame.insert(loc, column, value, allow_duplicates=False)
loc: 열을 삽입할 위치를 지정합니다. 정수로 위치를 나타냅니다.
column: 삽입할 열의 이름을 지정합니다.
value: 열에 넣을 데이터를 지정합니다. 이는 스칼라 값, 배열 또는 Series가 될 수 있습니다.
allow_duplicates: 기본적으로 False로 설정되어 있으며, 중복된 열 이름을 허용하지 않도록 합니다.
7-2 필요없어진 데이터는 삭제
- 값을 다 더했기 때문에 시간당 데이터 삭제
- X,Y좌표는 최종 데이터로서 필요한데 왜 삭제하는가 : 이후 값이 행으로서 여러 번 합쳐지기 때문에 좌표도 숫자로서 합쳐지므로 이후 좌표를 최종 직전에 merge 해주는 것이 좋음.

7-3 정류장별로 데이터를 합치기
- 최종 데이터 프레임은 정류장별 승하차 승객수를 다 합쳐서 보여줄 것을 요청했으므로, 정류장별로 하나의 데이터가 되도록 다음과 같이 groupby를 실시한다.

7-4 시간 데이터를 분기별로 합치기
- 최종 데이터 프레임은 또한 월별이 아니고 분기별로 보여줄 것을 요청했다. 3가지 월이 분기별로 하나의 데이터가 되도록 다음과 같이 groupby를 실시한다.
# 분기를 만드는 함수
def make_quarter(year_month):
# 정수를 문자열로 변환 하여 슬라이싱하고 함수 적용을 위해 다시 정수로 반환
month = int(str(year_month)[4:])
if month in [1, 2, 3]:
return '1분기'
elif month in [4, 5, 6]:
return '2분기'
elif month in [7, 8, 9]:
return '3분기'
elif month in [10, 11, 12]:
return '4분기'
# 데이터프레임에 분기 컬럼 추가
temp_group['분기'] = temp_group['사용년월'].apply(make_quarter)
temp_group
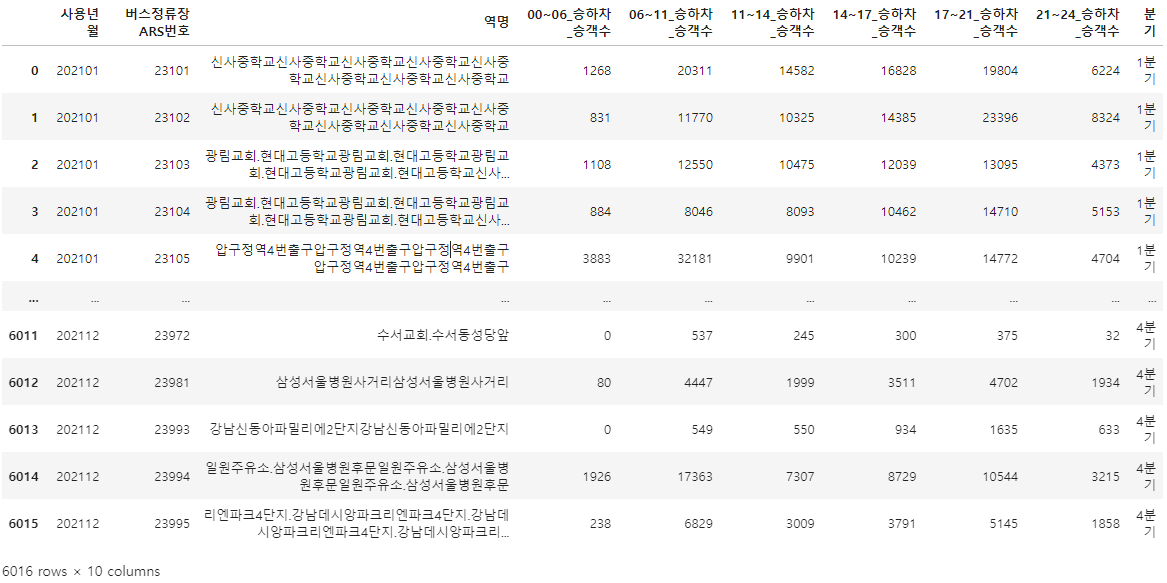
- 잘 만든 분기 컬럼을 앞쪽으로 이동해주는 겸 필요한 컬럼을 제외하고 컬럼 순서를 재배치 해주자.
# 역명 컬럼 삭제
# 사용연도는 그냥 나중에 다 하고 추가하는 것이 편함.
# 컬럼순서 정의
column_order = ['분기', '버스정류장ARS번호', '00~06_승하차_승객수',
'06~11_승하차_승객수', '11~14_승하차_승객수', '14~17_승하차_승객수',
'17~21_승하차_승객수', '21~24_승하차_승객수']
# 데이터프레임의 컬럼 순서를 재정렬
temp_group = temp_group[column_order]
temp_group
- 최종으로 분기별/정류장별 데이터를 다음과 같이 합칠 수 있다.

8. 잃어버린 데이터를 찾아서
8-1 X, Y 좌표 를 찾아서
- 다음 데이터 프레임(whkvy2)은 이전에 6번에서 만들었던 수작업으로 결측치를 채워주었던 temp3_mod 데이터 프레임에서 버스정류장 ARS번호와 X,Y좌표 값만을 남긴 CSV 파일이다. 이후 merge하는 데에 용이하도록 파일을 만들어두었다.

- 그렇지만 현재 중복된 값들이 남아있어 아직도 merge에 불편해보인다. 다음과 같이 중복 데이터를 제거하자

- 이후 버스 데이터를 기준으로 left merge 해주면 다음과 같이 잃어버렸던 좌표 값들을 추가할 수 있다.

8-2 연도 데이터를 찾아서
- 사실 연도 데이터를 찾는다고 하기도 이상하긴 하다. 해당 데이터는 아주 쉽게 추가해줄 수 있기 때문이다.
- 우리는 연도별로 데이터를 작업했기 때문에 다음과 같이 코드를 실행하여 연도 데이터를 추가해줄 수 있다.

9. 최종 데이터 정리
9-1 연도별 데이터 정리
- 최종으로 필요한 데이터는 모두 수집하고, 제거하고, 추가하고, 합치는 것을 완료했다.
- 다음과 같이 하나의 연도 데이터(2021년 데이터 기준)의 최종 데이터 프레임 생성을 완료하도록 하자.
# 컬럼순서 최종 정의
column_order = ['연도', '분기', '버스정류장ARS번호', '00~06_승하차_승객수',
'06~11_승하차_승객수', '11~14_승하차_승객수', '14~17_승하차_승객수',
'17~21_승하차_승객수', '21~24_승하차_승객수', 'X좌표', 'Y좌표']
# 데이터프레임의 컬럼 순서를 재정렬
result2 = result2[column_order]
result2

- 그리고 다음과 같이 데이터를 CSV 파일로 저장해주도록 하자.
result2.to_csv('data/bus_data/GNBus_2021.csv', index=False)
9-2 데이터 합치기
- 최종데이터는 2020~2022년 강남구 연도별/분기별/정류장별/시간 구간대별 승하차 승객수/정류장X좌표/ 정류장Y좌표 이다.
- 먼저 잘 만들어준 강남버스 데이터 연도별 데이터들을 불러온다.

- 다음과 같이 concat을 이용하여 3개년 데이터를 합치면 최종 완성이 되겠다.

'프로젝트 > (세미)강남구 지역 상권 기반 시간대별 편의점 매출 예측' 카테고리의 다른 글
| 3. 프로젝트 회의 정리(09.06) (0) | 2023.09.06 |
|---|---|
| 좌표 데이터(.shp) - 1 폴리곤 좌표를 파이썬으로 가져오기 (0) | 2023.09.06 |
| 2. 프로젝트 회의 정리(09.04-5) (0) | 2023.09.05 |
| 1. 프로젝트 회의 정리(09.03) (0) | 2023.09.03 |
| 0. 프로젝트 시작과 사전에 논의된 내용 (0) | 2023.08.31 |



