
- 이번 글에서는 이전까지 배웠던 기본적인 머신러닝 지식을 이용하여, 주어진 데이터를 이용하여 처음부터 끝까지 실습을 가볍게 실시해보도록 하겠다.
1. 데이터 불러오기
- 다음과 같이 먼저 train data 를 불러오자
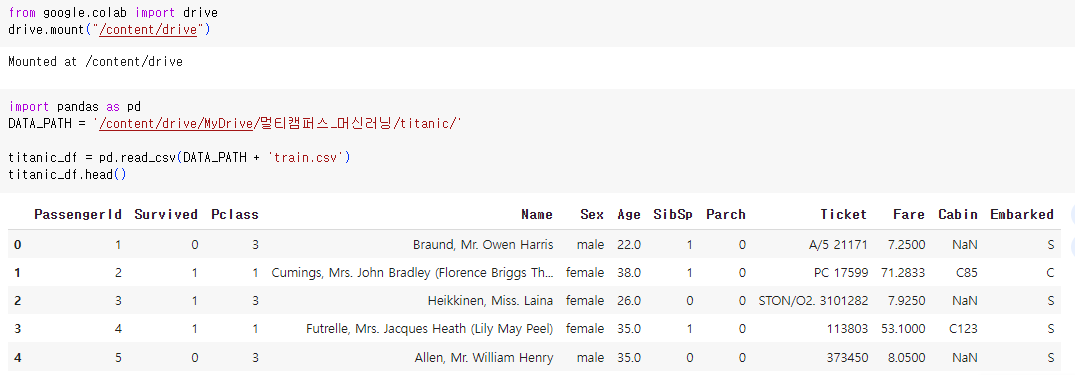
2. 데이터 파악


3. 데이터 가공하기
3-1 결측치 처리
- 이전에 확인했던 것처럼 타이타닉 데이터에는 결측치가 많다. 나이는 평균나이로, 나머지는 N 값으로 변경해주자(결측치 처리에 명확한 정답은 없음)

3-2 범주형 데이터 처리
- Sex 나 Embarked는 문제가 없어보이지만, Cabin값은 N이 독보적으로 687건을 기록하고있고, 여러 Cabin이 한꺼번에 기록되는 등 제대로 정리되지 않은 것으로 보인다.

- Cabin 의 경우 선실의 등급을 나타내는 것으로 가장 첫 알파벳이 중요한 데이터이므로, 다음과 같이 데이터를 재분류해보도록 하자.

4. 탐색적 데이터 분석
- 머신러닝 알고리즘 예측 전 데이터를 먼저 탐색해보도록 하자.
- 첫번째로는 어떤 유형의 승객이 생존 확률이 높았는지에 대해 확인해본다.
4-1 성별과 생존확률
- 성별과 생존 확률의 관계는 다음과 같이 살펴볼 수 있다.

4-2 부유함과 생존확률(+성별)
- 부유함과 가장 밀접하게 관련있는 것이 객실 등급이라고 할 수 있다. 단순히 등급별 생존 확률 보다 성별과 함께 고려해 분석하는 것이 효율적일 것 같아 객실 등급별 성별에 따른 생존 확률을 알아보겠다.
- 여성의 경우 일, 이등실의 차이는 크지 않으나 삼등실의 경우 생존 확률이 상대적으로 많이 차이가 난다.
- 남성의 경우 일등실의 생존 확률이 이, 삼등실보다 월등히 높은 것을 확인할 수 있다.

4-3 나이와 생존확률
- Age의 경우 값 종류가 많아, 범위별로 분류해서 카테고리 값으로 할당하여 진행하도록 하자. Age Category 시리즈는 분석 이후 삭제(.drop) 했다.
from tables import group
# 입력 Age 에 따라 구분 값을 반환하는 함수 설정. DataFrame 의 apply lambda 식에 사용
def get_category(age):
cat = ''
if age <= -1: cat = 'Unknown'
elif age <= 5: cat = 'Baby'
elif age <= 12: cat = 'Child'
elif age <= 18: cat = 'Teenager'
elif age <= 25: cat = 'Student'
elif age <= 35: cat = 'Young Adult'
elif age <= 60: cat = 'Adult'
else : cat = 'Elderly'
return cat
# 막대그래프의 크기 figure를 더 크게 설정
# plt.figure(figsize=(10,6))
# X 축의 값을 순차적으로 표시하기 위한 설정
group_names = ['Unknown', 'Baby', 'Child', 'Teenager', 'Student', 'Young Adult', 'Adult', 'Elderly']
# lambda 식에 위에서 생성한 get_category() 함수를 반환값으로 지정
# get_category(X)는 입력값으로 'Age' 컬럼 값을 받아서 해당하는 cat 반환
titanic_df['Age_cat'] = titanic_df['Age'].apply(lambda x : get_category(x))
fig, ax = plt.subplots(figsize=(10,6))
sns.barplot(x='Age_cat', y='Survived', hue='Sex', data=titanic_df, order = group_names)
titanic_df.drop('Age_cat', axis = 1, inplace = True)
- 아쉽게도 여자 child의 경우 다른 연령대에 비해 생존 확률이 비교적 낮았고, 여자 elderly의 경우 매우 생존확률이 높았다.
- 지금까지 분석해본 결과 sex / age / pclass가 생존을 좌우하는 피처로서 중요함을 확인할 수 있었다.
5. 데이터 인코딩
- 남아있는 문자열 카테고리 피처를 숫자형 카테고리 피처로 변환하도록 하자. LabelEncoder 클래스를 이용하여 다음과 같이 변환할 수 있다.

6. 불필요한 컬럼 제거
- 고유 값을 가지는, 예측에 필요없는 컬럼을 제거

7. 데이터 전처리 함수 생성
- 지금까지 피처를 가공한 것을 정리하고 이를 함수로 만들어 쉽게 재사용할 수 있도록 하자.

8. 머신러닝
8-1 데이터 준비

8-2 데이터 추출

8-3 알고리즘 적용하여 예측
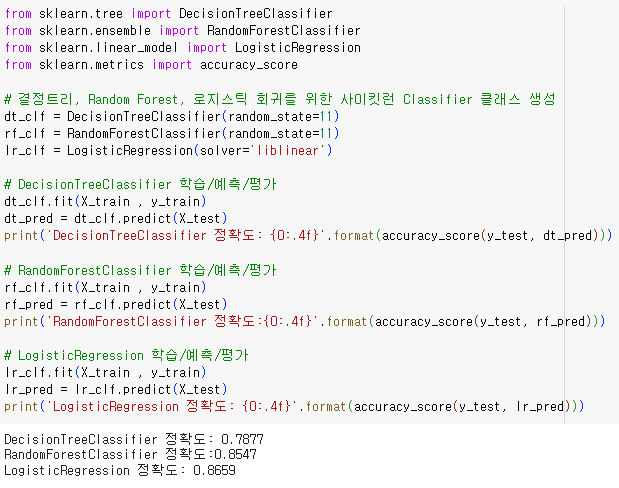
- print('LogisticRegression 정확도: {0:.4f}'.format(accuracy_score(y_test, lr_pred))) :
알고리즘 별 계산한 정확도를 출력합니다. format 메서드를 사용하여 출력 문자열의 포맷을 지정하고, 소수점 이하 4자리까지 표시하도록 하였습니다.
- 3개의 알고리즘 중 LogisticRegression이 타 알고리즘에 비해 높은 정확도를 나타내지만, 데이터양도 충분치 않기 때문에 어떤 알고리즘이 가장 성능이 좋다고 평가하는 건 조금 어렵다.
* 앞으로 프로젝트에서는 모든 머신러닝 알고리즘을 다 공부해야 할까?
정확도 높은 친구들만 공부하면 된다, 알고리즘은 정형화된 툴이 있다고 생각하면 편하다.
- 대표적인 5-6가지 알고리즘
- Regression
- LogisticRegression
- RandomForest
- DecisionTree
- LightGBM (옵션 : XGboost) <---SGD
그중에서도 또 핵심만 공부하고 싶다 ? = Regression / LightGBM
- LightGBM XGboost는 데이터 수에 따라 취사선택을 잘 해보라는 의견도 있었음(XGboost 의 속도 개선 이 LightGBM은 맞음)
※ 수치 예측 프로젝트
: Regression & LightGBM
※ 분류 예측 프로젝트
: LogisticRegression & LightGBM
이 글은 파이썬 머신러닝 완벽 가이드 개정 2판(권철민, 2022)을 일부 참고하여 작성하였습니다.
'IT & 개발공부 > 파이썬(Python)' 카테고리의 다른 글
| 머신러닝 알고리즘(선형회귀, 결정트리 등) 이해하기 (0) | 2023.08.21 |
|---|---|
| 머신러닝 모델 평가하기(분류 모델 평가 당뇨 예측 실습) (0) | 2023.08.20 |
| 머신러닝에서의 데이터 전처리 (0) | 2023.08.18 |
| 머신러닝과 교차검증(+ 하이퍼 파라미터 튜닝) (0) | 2023.08.17 |
| 파이썬 머신러닝 배경 지식 & 탐색적 자료 분석 (1) | 2023.08.16 |



